語音信號(hào)識(shí)別基于盲源信號(hào)分離的實(shí)現(xiàn)

摘要:為了識(shí)別兩路頻譜混疊語音信號(hào),多采用盲信號(hào)分離的方法。但是該方法在工程實(shí)踐中實(shí)現(xiàn)較困難。因此給出了一種利用盲源信號(hào)分離的原理及特點(diǎn)的實(shí)現(xiàn)方法,具體說明了用FastICA算法在ADSP_BF533平臺(tái)上實(shí)現(xiàn)盲源信號(hào)分離時(shí)的具體流程。該設(shè)計(jì)方案所需時(shí)間短,效率高,而且占用內(nèi)存較少。
關(guān)鍵詞:盲信號(hào)分離;DSP;FastICA;ADSP_BF533平臺(tái)
0 引言
近年來,許多學(xué)者都針對(duì)盲信號(hào)分離不斷地提出新的理論算法,盲信號(hào)分離(BSS)發(fā)展也日趨完善。而用DSP器件實(shí)現(xiàn)這種技術(shù)具有很大意義。本文提出了盲源信號(hào)分離的實(shí)現(xiàn)原理、算法和實(shí)現(xiàn)步驟,并對(duì)利用DSP實(shí)現(xiàn)時(shí)經(jīng)常出現(xiàn)的問題提出了解決方案。
盲信號(hào)分離是指在傳輸信道特性和輸入信息未知或者僅有少量先驗(yàn)知識(shí)的情況下,只由觀測(cè)到的輸出信號(hào)來辨識(shí)系統(tǒng),以達(dá)到對(duì)多個(gè)信號(hào)分離的目的,從而恢復(fù)原始信號(hào)或信號(hào)源。它是一種在神經(jīng)網(wǎng)絡(luò)和統(tǒng)計(jì)學(xué)基礎(chǔ)上發(fā)展起來的技術(shù),并在近十年來獲得了飛速發(fā)展。盲源信號(hào)分離對(duì)很多領(lǐng)域的多信號(hào)處理與識(shí)別提供了很大方便。該技術(shù)在通信、生物醫(yī)學(xué)信號(hào)處理、語音信號(hào)處理、陣列信號(hào)處理以及通用信號(hào)分析等方面有著廣泛的應(yīng)用前景。它不僅對(duì)信號(hào)處理的研究,而且也對(duì)神經(jīng)網(wǎng)絡(luò)理論的發(fā)展起著積極的推動(dòng)作用。
1 盲源信號(hào)分離的數(shù)學(xué)模型及常見算法
1.1 數(shù)學(xué)模型
盲分離問題的研究內(nèi)容大體上可以劃分為瞬時(shí)線性混疊盲分離、卷積混疊盲分離,非線性混疊盲分離以及盲分離的應(yīng)用四部分。當(dāng)混疊模型為非線性時(shí),一般很難從混疊數(shù)據(jù)中恢復(fù)源信號(hào),除非對(duì)信號(hào)和混疊模型有進(jìn)一步的先驗(yàn)知識(shí)。圖1所示是瞬時(shí)線性混疊盲分離信號(hào)模型示意圖。
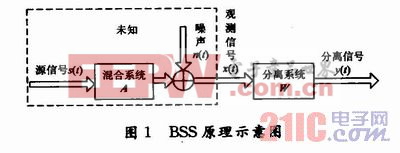
圖1中,S=[s1(t),s2(t),…,sN(t)]T是未知的N維源信號(hào)向量,A是未知的混合矩陣,n=[n1(t),n2(t),…,nN(t)]T是M維噪聲向量,X=[x1(t),x2(t),…,xM(t)]T是傳感器輸出的M維觀測(cè)信號(hào)向量,有X=AS+n,盲源分離算法要求只知道X來確定S或A。獨(dú)立分量分析(Independent ComponentAnalysis,ICA)是BSS的一種,其基本含義是把信號(hào)分解成若干個(gè)互相獨(dú)立的成分。圖1中,ICA的目標(biāo)就是尋找一個(gè)分離矩陣W,使X經(jīng)過變換后得到的新矢量Y=[y1(t),y2(t),…,yN(t)]T的各分量盡可能的獨(dú)立。Y=WX為待求的分離信號(hào)向量,也就是源信號(hào)S的估計(jì)值。
1.2 盲信號(hào)預(yù)處理常見算法
在盲信號(hào)處理過程中,為了減少計(jì)算量,提高系統(tǒng)效率,通常需要經(jīng)過預(yù)處理。預(yù)處理一般包括中心化和白化。中心化是使信號(hào)的均值為零。由于在一般情況下所獲得的數(shù)據(jù)都具有相關(guān)性,所以通常都要求對(duì)數(shù)據(jù)進(jìn)行初步的白化處理,因?yàn)榘谆幚砜扇コ饔^測(cè)信號(hào)之間的相關(guān)性,從而簡化后續(xù)獨(dú)立分量的提取過程。而且,通常情況下,對(duì)數(shù)據(jù)進(jìn)行白化處理與不對(duì)數(shù)據(jù)進(jìn)行白化處理相比,其算法的收斂性較好、工作量少、效率高。
線性混疊盲分離信號(hào)模型一般都采用獨(dú)立分量分析的方法。ICA的主要依據(jù)和前提是假設(shè)源信號(hào)是獨(dú)立的,因此,自然就可以設(shè)想ICA算法的第一步是建立目標(biāo)函數(shù)來表征分離結(jié)果的獨(dú)立程度。目標(biāo)函數(shù)確定后,可通過各種不同的優(yōu)化算法進(jìn)行優(yōu)化,進(jìn)而確定分離矩陣W,其中有代表性的算法主要有最大信息量(Infomax)法、自然梯度法、快速獨(dú)立元分析算法(FastICA)、矩陣特征值分解法等。盲分離中經(jīng)常要用到優(yōu)化運(yùn)算,就優(yōu)化手段而言,Infomax算法、自然梯度算法屬于梯度下降(上升)尋優(yōu)算法,收斂速度是線性的,速度略慢一些,但屬于自適應(yīng)方法,且具有實(shí)時(shí)在線處理能力;FastICA算法是一種快速而數(shù)值穩(wěn)定的方法,采用擬牛頓算法實(shí)現(xiàn)尋優(yōu),具有超線性收斂速度,通常收斂速度較梯度下降尋優(yōu)算法快得多;矩陣特征值分解方法一般通過對(duì)矩陣進(jìn)行特征分解或者廣義特征分解來估計(jì)分離矩陣,這是一種解析方法,可直接找到閉形式解(Closed Form Soutions),由于其沒有迭代尋優(yōu)過程,因此運(yùn)行速度最快。
2 盲源信號(hào)分離的DSP實(shí)現(xiàn)方法
2.1 實(shí)現(xiàn)原理
由于FastICA算法和其他的ICA算法相比,具有許多人們期望的特性:如收斂速度快、無需選步長參數(shù)、能夠通過選擇適當(dāng)?shù)姆蔷€性函數(shù)g來最佳化、能減小計(jì)算量等。同時(shí)也有許多神經(jīng)算法的優(yōu)點(diǎn),如并行、分布式且計(jì)算簡單,內(nèi)存要求很少等。因此,F(xiàn)astICA得到了廣泛的應(yīng)用。本文就采樣了這種算法。
2.2 實(shí)現(xiàn)方法
基于負(fù)熵最大的FastICA算法的基本原理是基于中心極限定理。即:若一隨機(jī)變量X由許多相互獨(dú)立的隨機(jī)變量Si(i=1,2,…,N)之和組成,那么,只要Si具有有限的均值和方差,則不論其為何種分布,隨機(jī)變量X較Si更接近高斯分布。由信息論理論可知;在所有等方差的隨機(jī)變量中,高斯變量的熵最大,因而可以利用熵來度量非高斯性,常用熵的修正形式,即負(fù)熵。因此,在分離過程中,可通過對(duì)分離結(jié)果的非高斯性度量來表示分離結(jié)果間的相互獨(dú)立性,當(dāng)非高斯性度量達(dá)到最大時(shí),表明已完成對(duì)各獨(dú)立分量的分離。





評(píng)論