RFID中解決無線信道爭用問題的防碰撞算法研究

摘要:RFID技術(shù)中的防碰撞算法分為閱讀器的防碰撞以及標簽的防碰撞兩種。文章通過對RFID中各種主流防碰撞方法的思想、實現(xiàn)及算法的研究,在現(xiàn)有的二進制搜索算法的基礎(chǔ)之上,提出了一種改進算法,并對改進算法的實現(xiàn)進行了Matlab仿真。結(jié)果證實:改進后的算法相較其他算法在標簽長度較短的情況下,可以表現(xiàn)出極其優(yōu)越的性能。
關(guān)鍵詞:RFID;防碰撞;二進制搜索算法;改進算法
0 引言
RFID系統(tǒng)主要由讀寫器和射頻卡兩部分組成,它們之間可以通過無線方式進行通信。其中,射頻卡中存儲了需要識別、交互的數(shù)據(jù),并且可以實時寫入或擦除。RFID系統(tǒng)工作時,若有多個電子標簽同時在同一個閱讀器的作用范圍內(nèi)向閱讀器發(fā)送數(shù)據(jù),則往往會出現(xiàn)信號的干擾,這個干擾就被稱為碰撞,其結(jié)果將會導(dǎo)致此次數(shù)據(jù)傳輸?shù)氖。蚨仨毑捎眠m當?shù)募夹g(shù)防止碰撞。最近,有人提出了動態(tài)二進制搜索法、跳躍式類二進制搜索法等二進制防碰撞算法的改進算法。國際上廣泛應(yīng)用的防碰撞算法是ALOHO法和二進制搜索法及對這兩種算法的改進方法,如時隙ALOHO法、動態(tài)二進制搜索法、后退式二進制法搜索等。其中,動態(tài)二進制法是國際標準所推薦的防碰撞方法。就此,本文提出了一種二進制搜索法的改進型算法。
1 二進制搜索算法
1.1 二進制搜索算法(BS)原理
二進制搜索算法又稱為二叉樹搜索算法。由于它要求能夠在閱讀器中確定數(shù)據(jù)碰撞位的準確位置,因此,必須要有合適的位編碼法。曼徹斯特碼用上升沿表示0,用下降沿表示1,在數(shù)據(jù)傳輸過程中不允許“沒有改變”的狀態(tài)。如果采用ASK調(diào)制方式,當多個電子標簽同時發(fā)送的數(shù)據(jù)位值不同時,則對應(yīng)的曼徹斯特碼的上升沿和下降沿相互抵消,造成一種錯誤的狀態(tài),從而可以確定碰撞位置。假設(shè)有兩個編碼為8位的電子標簽,利用曼徹斯特編碼識別碰撞位的原理如圖1所示。閱讀器檢出的碰撞位為D6位和D5位。
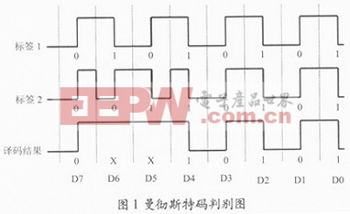
一般情況下,二進制搜索算法必須先能辨認出閱讀器中數(shù)據(jù)沖突的確切位置,這一點是下面算法的基礎(chǔ)。這里主要對以下幾個命令以及原理流程進行簡述:
REQUEST(某序列號Q):如果標簽序列號小于或等于Q,則該標簽進入識別狀態(tài),將發(fā)自己的序列號給閱讀器,否則處于等待狀態(tài);
SELECT(某序列號Q):如果標簽序列號等于Q,則該標簽進入選中狀態(tài),否則繼續(xù)等待識別;
READ:選中的標簽與閱讀器進行數(shù)據(jù)通信;
UNSELECT:取消前選中標簽,該標簽進入靜默狀態(tài),待所有標簽完成通信或者該標簽重新入場后,才能進入等待狀態(tài)。
1.2 二進制搜索算法的深入分析
閱讀器和標簽之間的通信次數(shù)決定了識別速度。從眾多標簽中識別出一個標簽的平均通信次數(shù)為L。在二進制搜索算法中,我們知道:
L=log2N+1 (1)
由于二進制搜索算法的識別獨立性,N個標簽的全部識別平均通信次數(shù)為:
![]()
當標簽數(shù)目很多的時候,由于每次獨立識別浪費了大量通信次數(shù),算法總的通信次數(shù)必然會增長很快。二進制搜索算法還有一個很明顯的弱點:閱讀器發(fā)送給每個標簽的比較序列,其實有用的信息只包含在高于上次碰撞位X的高位之中,低于碰撞位的通信產(chǎn)生冗余。
2 動態(tài)二進制搜索算法
2.1 動態(tài)二進制搜索算法原理
前面所述的二進制搜索算法,每次搜索都需要完整的傳輸標簽的序列號ID。但在實際應(yīng)用中,標簽的序列號長度不再像前所述那樣為8位,而可能是長達10個字節(jié)甚至更大的規(guī)模。這樣采用BS算法,RFID系統(tǒng)標簽的傳輸量將大增,為此動態(tài)二進制搜索(DBS)算法應(yīng)運而生。D BS算法是IS014443A這一國際標準所推薦的防碰撞算法。序列號ID中的全部信息對于成功識別出標簽不是不可或缺的。根據(jù)編碼規(guī)律可以去掉序列號中的冗余信息,留下有用的信息傳輸。通過觀察上面BS算法實例中標簽的識別過程可知:命令中的碰撞位及其低位因為總是被置位為1,不包含有用的信息,這樣就不要傳輸;標簽應(yīng)答的序列號最高位至碰撞位是已知的前綴信息,不包括補充信息,也不需要傳輸。由上面的分析可知,序列號ID中的冗余部分是不需要傳輸?shù)摹?梢詫BS算法由雙向的完整傳輸加以改進,只傳輸部分有用信息。Request命令中,讀寫器只需以要搜索的序列號ID的碰撞位至最高位部分為參數(shù)。所有相應(yīng)位與此命令中參數(shù)相符的標簽,則傳輸序列號的碰撞位以下部分作為應(yīng)答。
2.2 DBS算法的命令
與BS算法的命令相比,DBS算法的命令做了一些改進:主要是DBS算法把第一個命令改成Request(IDn-x,X)。讀寫器發(fā)送參數(shù)IDn-x(ID的N-X位)給作用范圍內(nèi)的所有標簽,相應(yīng)位與IDn-x符合的標簽做出響應(yīng),返回剩余的位信息。其余三條命令與前面所述BS算法一致。
2.3 DBS算法的性能分析
DBS算法與BS算法的規(guī)則相同,所以兩者重復(fù)操作的過程也相同。因此,DBS算法的總搜索次數(shù)為:
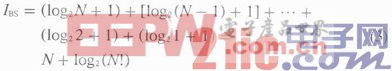
DBS算法在識別過程開始時,即算法的第一步,工作范圍內(nèi)的標簽是需要傳輸整個序列號的;在這之后的識別過程中,標簽只需要傳輸ID的有用部分位。整個識別過程平均下來,DBS的信息量只有BS算法的一半。DBS算法中,標簽要傳輸?shù)臄?shù)據(jù)量和所需時間比起B(yǎng)S算法減少了近50%。





評論