基于嵌入式系統(tǒng)的語音口令識別系統(tǒng)的實(shí)現(xiàn)

摘要:語音口令識別是信息處理的一個(gè)重要研究方向,本文給出一種基于嵌入式系統(tǒng)的語音口令識別系統(tǒng)的設(shè)計(jì)方案,硬件系統(tǒng)的核心芯片是嵌入式微處理器,語音口令識別算法采用連續(xù)隱馬爾克夫模型。實(shí)驗(yàn)結(jié)果表明,將語音識別系統(tǒng)與嵌入式系統(tǒng)相結(jié)合,可以使語音口令識別系統(tǒng)廣泛應(yīng)用于便攜式設(shè)備中。
關(guān)鍵詞:語音口令識別;嵌入式系統(tǒng):隱馬爾克夫模型
0 引言
隨著計(jì)算機(jī)技術(shù)和信息技術(shù)的迅速發(fā)展,語音口令識別已經(jīng)成為了人機(jī)交互的一個(gè)重要方式之一。語音口令識別系統(tǒng)將根據(jù)人發(fā)出的聲音、音節(jié)或短語給出響應(yīng),如通過語音口令控制一些執(zhí)行機(jī)構(gòu)、控制家用電器的運(yùn)行或做出回答等。在數(shù)字信號處理芯片上已經(jīng)實(shí)現(xiàn)了語音口令識別系統(tǒng)或語音口令識別系統(tǒng)的部分功能,然而隨著嵌入式微處理器處理能力的大幅度提高,計(jì)算量大的語音口令識別算法已經(jīng)能夠通過嵌入式微處理器來完成,將語音口令識別系統(tǒng)與嵌入式系統(tǒng)相結(jié)合,發(fā)揮語音識別系統(tǒng)的潛力,使語音識別系統(tǒng)能夠廣泛應(yīng)用于便攜式設(shè)備中。
采用隱馬爾克夫模型(Hidden Markov Model,HMM)描述語音信號的非平穩(wěn)性和局部平穩(wěn)性,HMM中的狀態(tài)與語音信號的某個(gè)平穩(wěn)段相對應(yīng),平穩(wěn)段之間以轉(zhuǎn)移概率相聯(lián)系。由于HMM建模對語音信號長度和模型的混合度的要求都比較低,因此在現(xiàn)有的非特定人語音口令識別系
統(tǒng)中,多采用狀態(tài)輸出具有連續(xù)概率分布的連續(xù)隱馬爾可夫模型(Continuous Density Hidden Markov Model,CDHMM)。
論文給出一種基于嵌入式系統(tǒng)的語音口令識別系統(tǒng)的設(shè)計(jì)方案,硬件系統(tǒng)的核心芯片是嵌入式微處理器,語音口令識別算法采用CDHMM。語音口令首先經(jīng)過預(yù)處理,提取MFCC(Mel-Frequency Ceptral Coefficients)特征參數(shù),然后建立此口令的CDHMM模型,把所有語音口令的模型放在模型庫中,在識別階段,通過概率輸出評分,取評分最大的一個(gè)作為識別出的口令。將語音識別系統(tǒng)與嵌入式系統(tǒng)相結(jié)合,可以使語音口令識別系統(tǒng)廣泛應(yīng)用于便攜式設(shè)備中。
1 硬件電路的設(shè)計(jì)和工作原理
基于嵌入式系統(tǒng)的語音口令識別系統(tǒng)需要有接收語音信號的輸入芯片配合麥克風(fēng)實(shí)現(xiàn)將模擬語音信號轉(zhuǎn)換成數(shù)字信號的功能,然后由嵌入式微處理器對輸入的語音口令信號進(jìn)行處理。完成語音口令信號輸入功能的芯片采用的是PHILIPS公司的低功耗芯片UDAl341TS,供電電源電壓為3V,該音頻處理芯片由模數(shù)/數(shù)模轉(zhuǎn)換(ADC)、控制邏輯電路、可編程增益放大器(PGA)和數(shù)字自動增益控制器(DAGC)以及數(shù)字信號處理器等部分組成,能進(jìn)行數(shù)字語音處理。
芯片UDAl341TS采用標(biāo)準(zhǔn)的內(nèi)部集成電路聲音總線IIS(Inter IC Sound Bus),該總線是由PHILIPS等公司共同提出的數(shù)字音頻總線協(xié)議,專門用于音頻設(shè)備之間的數(shù)據(jù)傳輸,目前很多音頻芯片和微處理器都提供了對IIS總線的支持。
IIS總線有三根信號線,分別是位時(shí)鐘信號BCK(Bit Clock)、字選擇控制信號WS(Word Select)和串行數(shù)據(jù)信號Data,由主設(shè)備提供串行時(shí)鐘信號和字選擇控制信號,IIS總線的時(shí)序如圖1所示。
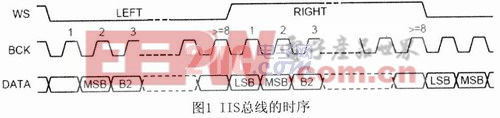
WS也稱為幀時(shí)鐘信號,該信號的電平為低電平時(shí),傳輸?shù)妮斎胍纛l數(shù)據(jù)信號是左聲道的音頻數(shù)據(jù)信號;信號WS的電平為高電平時(shí),傳輸?shù)妮斎胍纛l數(shù)據(jù)信號是右聲道的音頻數(shù)據(jù)信號。BCK對應(yīng)著輸入音頻數(shù)據(jù)信號的每一位音頻數(shù)據(jù),其頻率為2×采樣頻率×每個(gè)采樣值的位數(shù)。
與BCK同步的串行音頻數(shù)據(jù)信號采用補(bǔ)碼的形式傳輸,傳輸順序是高位先傳輸。IIS總線格式的信號無論有多少位有效數(shù)據(jù),數(shù)據(jù)的最高位MSB總是出現(xiàn)在WS信號改變(也就是傳輸一幀數(shù)據(jù)信號開始)后的第2個(gè)串行數(shù)據(jù)信號SCLK脈沖位置。

評論