基于Windows CE的語音口令識別系統(tǒng)的設計

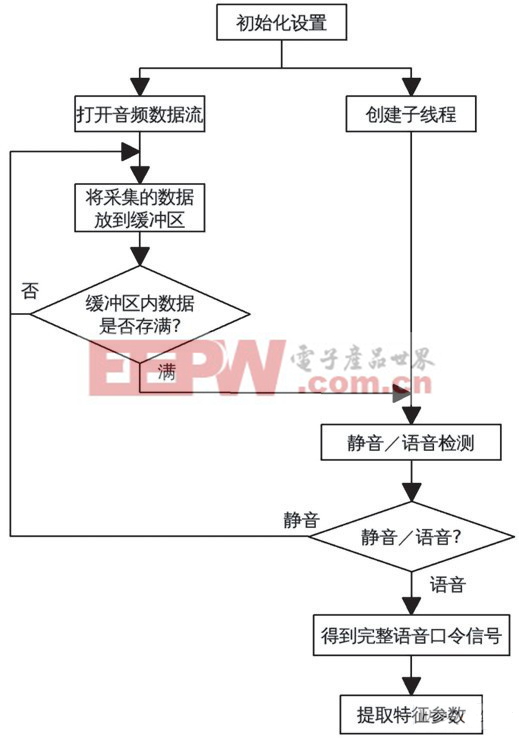
圖2 信號的采集和處理流程圖。
主程序在配置好初始化參數(shù)后,建立一個子線程,建立子線程有利于將靜音檢測的復雜運算過程和主程序的音頻數(shù)據(jù)采集過程分開進行,以確保在靜音檢測時不會丟掉音頻數(shù)據(jù)。與此同時,主程序開始采集數(shù)據(jù),并存入到緩沖區(qū)。當預先設定好的緩沖區(qū)內(nèi)的數(shù)據(jù)采集滿后,會將所采集的數(shù)據(jù)交給子線程,子線程做靜音檢測判斷。主程序會依然繼續(xù)重新采集新的音頻數(shù)據(jù)。對于子線程,子線程的任務是等待主程序發(fā)出命令,然后對數(shù)據(jù)做處理。如果檢測到有語音口令的開始,會繼續(xù)采集數(shù)據(jù),得到完整命令語音口令信號,提取相應的特征參數(shù)。
具體程序中有如下幾個主要過程:
(1)初始化參數(shù)設置:
(a)FuncReturn=waveInOpen((Record_Buffer_Manager.hWaveIn),WAVE_MAPPER,wFormat,(LONG)(RecordBufferFillProc),(DWORD)this,CALLBACK_FUNCTION);//首先要調(diào)用API函數(shù)打開音頻設備接口,并且設置相應的回調(diào)(CALLBACK)函數(shù)(回調(diào)函數(shù)是操作系統(tǒng)在每次緩沖區(qū)存滿后會自動訪問的一個特殊函數(shù))
(b)Thread_process=AfxBeginThread((AFX_THREADPROC)RecordThreadProc,(LPVOID)this,THREAD_PRIORITY_NORMAL,0,0,0);//要為其單獨建立一個線程,為了實現(xiàn)靜音檢測,在混雜著環(huán)境噪聲的前提下,找出語音口令信號。
(c)FuncReturn=waveInStart(Record_Buffer_Manager.hWaveIn);//打開音頻數(shù)據(jù)流,開始錄音。(緩沖區(qū)存滿后,系統(tǒng)會自動訪問回調(diào)函數(shù))
(2)主程序與子線程通信
SetEvent(pRecord-》hRecordEvent );//發(fā)出信號,使得子線程函數(shù)得到命令,對采集到的音頻流進行靜音的檢測判斷。
(3)在子線程內(nèi)接收消息作出反應
WaitForSingleObject(pRecord-》hRecordEvent,INFINITE);ResetEvent(pRecord-》hRecordEvent);//與回調(diào)函數(shù)的信號發(fā)出程序?qū)邮苄盘枺⒅匦略O定狀態(tài),等待下一次信號。
……
pRecord-》ProcessData((SAMPLE_TYPE *)pRecord-》pLeftData,……);//將得到的數(shù)據(jù)段進行處理,也就是真正執(zhí)行靜音檢測的部分。
(4)得到完整語音口令信號后提取特征參數(shù)。
2 結(jié)束語
論文建立了一種基于Windows CE的語音口令識別系統(tǒng),并且對上升、下降等14條口令進行測試。實驗結(jié)果表明,本語音口令識別系統(tǒng)達到了實時的要求,可以廣泛應用于便攜式設備中。



評論