用DSP實現MPEG音頻層III壓縮的加速方法

1 概述
本文引用地址:http://www.104case.com/article/150148.htm數字音頻壓縮技術給人們提供了一種更為有效的音頻存儲、傳輸方法。音頻壓縮的技術有很多種,它們的復雜度、音頻壓縮質量、以及壓縮比都有很大的差別。如:μ-law音頻壓縮算法,其特點是簡單,但壓縮比很低,但音質一般。根據CCITT G.711建議,采用自然對數的量化過程,在輸入幅度比較小的時候能夠提供比較大精度的量化,而對于出現概率比較小的大幅度信號,量化噪聲相對而言則較大。這種量化方式使得8 bit的數字量化信號在量化噪聲效果上等同于14 bit的線性量化。而ADPCM壓縮編碼則充分利用了相鄰的抽樣值幅度變化比較小的特點,編碼輸出結果是當前抽樣值與預測值的差值。雖然ADPCM編碼的保真度較高,但其壓縮比卻比較小,只能夠達到4/1的壓縮比。改進的ADPCM編碼方法有IMA (Interactive Multimedia Association)提出的改進算法,CCITT的G.721,G.723建議等[1]。
MPEG(Motion Picture Expert Group)音頻壓縮標準提供了一種高保真度,高壓縮比的壓縮算法。在ISO11172-3標準中,描述了具有不同復雜度和性能的子帶音頻編碼方案,以適應各種高音質數字音頻的應用。根據編碼計算復雜度及編碼效率的不同,分為層I,層II和層III三種標準。
MPEG音頻標準最初來源于被分為四種類型的算法草案,它們是音頻頻域感覺熵編碼ASPEC(Audio Spectral Perceptual Entropy Coding),掩蔽模式通用子帶集成編碼與多路復用MUSICAM(Masking-pattern Universal Sub-band Integrated Coding and Multiplexing),子帶ADPCM SB/ADPCM(Sub-Band Adaptive Difference PCM)。經過一系列的客觀和主觀音質測試,考慮到不同比特率下的音質,對傳輸比特錯誤的敏感性,編碼/解碼復雜度,以及編解碼延時等因素,在大約100 kbit/s低碼率下,ASPEC和MUSICAM表現出最好的音質效果。在低碼率(64 kbit/s)時,ASPEC表現出更為出色的音質,而MUSICAM則在編碼解碼的復雜度和延時上略勝一籌。根據ASPEC的若干算法,對 MUSICAM進行改進,加大了計算復雜度,但獲得了更好的壓縮比及音質,這就是ISO11172-3音頻層III的標準。
層I是最簡單的一種算法。如Philips公司的數字盒式錄音機DCC(DIGItal Compact Cassette)便是利用層I的壓縮算法,其應用的比特率為192 kbit/s每通道。
層II具有中等的編碼復雜度,適用比特率大約為128 kbit/s每通道。廣泛應用于數字音頻廣播DAB(Digital Audio BroADCasting)的音頻編碼及視頻CD中。
層III是最復雜的編碼算法,但是在相同的比特率下,它所提供的音質也是最好的。典型的比特率為64 kbit/s,最適合于ISDN上的音頻傳輸。
1998年4月22日,APT(Audio Processing Technique)公司利用Apt-X100系統,通過ISDN線路,成功地轉播了北京—東京—上海的“國際地球日”大型廣播音樂會。但是,這次轉播占用了3條(即6個B)的ISDN線路,以保證22 kHz頻響的立體聲傳送,這是由于Apt-X100系統采用的是SB/ADPCM音頻壓縮方法[2]。然而,如果使用MPEG層III音頻壓縮方法,只需要一條ISDN線路,就可以實現22 kHz頻響的立體聲傳送。由于MPEG層III音頻壓縮編碼復雜度太高,運算量太大,難以用一般的DSP(Digital Signal Processor)單片實現,所以在目前的音響設備中很少使用這一算法。為了能用較低的成本實現MPEG層III這一高效音頻壓縮算法,我們對這一算法進行了全面分析,提出了適用于DSP實現的編碼加速方案。
2 MPEG音頻層III壓縮編碼流程及特點
MPEG音頻層III壓縮編碼流程如圖1所示,相對于層Ⅰ和層Ⅱ而言,其特點在于:
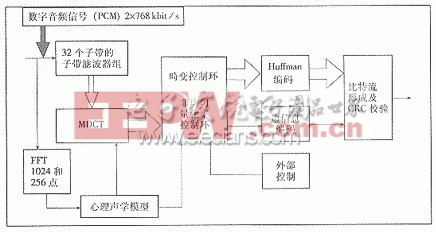
圖1 MPEG音頻層Ⅲ編碼流程圖(單聲道模型)
(1)利用獨立于信號頻率及聲壓級的耳蝸擴散函數(Cochlea spreading function)—Modified Rounded 類擴散函數,計算人耳聽覺的掩蔽門限。
(2)增加了MDCT模塊,以提高頻率分辨率。
(3)通過控制環,對非均勻量化率進行迭代分配,以保持相對恒定的信噪比。并且,采用不定長熵編碼—Huffman編碼,對量化后的各子帶信號可以獲得更好的數據壓縮比。
將層III編碼算法流程分成:(1)時頻映射,(2)心理聲學模型,(3)量化編碼等三大功能塊。時頻映射中,是多相混合濾波器組(Polyphase/MDCT Hybrid Filter Bank)的計算,這是較規范的計算,其運算量是可計算的。而且有各種快速算法,以降低運算復雜度。心理聲學模型的計算,主要運算量集中在1 024點和256點的FFT。不過,這是比較標準的計算過程,無論用哪種FFT都可以精確估計其運算復雜度。而量化編碼是通過迭代循環來完成,其循環控制變量是不確定的,再加上Huffman碼表的查找表過程,使其運算量和復雜度難以預測和估計。因此,我們認為:量化編碼部分的規范化是優化MPEG音頻層 III編碼的突破點。
層III編碼器迭代循環與量化編碼部分完成的功能是:將子帶濾波和MDCT變換后的樣值進行量化并根據心理聲學模型的計算結果進行量化噪聲的控制,使得在一定比特率要求的情況下完成頻域信號的Huffman編碼。層III量化編碼部分的迭代循環分為內循環和外循環,參考文獻[1]中FigureC. 9.a,C.9.b,C.9.c給出了量化編碼的迭代循環流圖。
3 用DSP實現音頻層III壓縮的主要問題及解決方案
DSP編程并不提供像C語言一樣的靈活指針、數組尋址操作。在用DSP實現音頻層III壓縮中的迭代循環量化編碼時,由于涉及到非規則性的大量數組尋址操作,而消耗大量指令,降低了DSP的利用率,抑制了編碼的實時實現。因此,不規則的類似表查詢指令,需要經過很好的組織才能夠使程序結構清楚,簡潔,高效。









評論