透過Linux內核看無鎖編程

多核多線程已經成為當下一個時髦的話題,而無鎖編程更是這個時髦話題中的熱點話題。Linux內核可能是當今最大最復雜的并行程序之一,為我們分析多核多線程提供了絕佳的范例。內核設計者已經將最新的無鎖編程技術帶進了2。6系統內核中,本文以2。6。10版本為藍本,帶領您領略多核多線程編程的真諦,窺探無鎖編程的奧秘,體味大師們的高雅設計!
本文引用地址:http://www.104case.com/article/149034.htm非阻塞型同步(Non-blockingSynchronization)簡介
如何正確有效的保護共享數據是編寫并行程序必須面臨的一個難題,通常的手段就是同步。同步可分為阻塞型同步(BlockingSynchronization)和非阻塞型同步(Non-blockingSynchronization)。
阻塞型同步是指當一個線程到達臨界區時,因另外一個線程已經持有訪問該共享數據的鎖,從而不能獲取鎖資源而阻塞,直到另外一個線程釋放鎖。常見的同步原語有mutex、semaphore等。如果同步方案采用不當,就會造成死鎖(deadlock),活鎖(livelock)和優先級反轉(priorityinversion),以及效率低下等現象。
為了降低風險程度和提高程序運行效率,業界提出了不采用鎖的同步方案,依照這種設計思路設計的算法稱為非阻塞型算法,其本質特征就是停止一個線程的執行不會阻礙系統中其他執行實體的運行。
當今比較流行的Non-blockingSynchronization實現方案有三種:
Wait-free
Wait-free是指任意線程的任何操作都可以在有限步之內結束,而不用關心其它線程的執行速度。Wait-free是基于per-thread的,可以認為是starvation-free的。非常遺憾的是實際情況并非如此,采用Wait-free的程序并不能保證starvation-free,同時內存消耗也隨線程數量而線性增長。目前只有極少數的非阻塞算法實現了這一點。
Lock-free
Lock-Free是指能夠確保執行它的所有線程中至少有一個能夠繼續往下執行。由于每個線程不是starvation-free的,即有些線程可能會被任意地延遲,然而在每一步都至少有一個線程能夠往下執行,因此系統作為一個整體是在持續執行的,可以認為是system-wide的。所有Wait-free的算法都是Lock-Free的。
Obstruction-free
Obstruction-free是指在任何時間點,一個孤立運行線程的每一個操作可以在有限步之內結束。只要沒有競爭,線程就可以持續運行。一旦共享數據被修改,Obstruction-free要求中止已經完成的部分操作,并進行回滾。所有Lock-Free的算法都是Obstruction-free的。
綜上所述,不難得出Obstruction-free是Non-blockingsynchronization中性能最差的,而Wait-free性能是最好的,但實現難度也是最大的,因此Lock-free算法開始被重視,并廣泛運用于當今正在運行的程序中,比如linux內核。
一般采用原子級的read-modify-write原語來實現Lock-Free算法,其中LL和SC是Lock-Free理論研究領域的理想原語,但實現這些原語需要CPU指令的支持,非常遺憾的是目前沒有任何CPU直接實現了SC原語。根據此理論,業界在原子操作的基礎上提出了著名的CAS(Compare-And-Swap)操作來實現Lock-Free算法,Intel實現了一條類似該操作的指令:cmpxchg8。
CAS原語負責將某處內存地址的值(1個字節)與一個期望值進行比較,如果相等,則將該內存地址處的值替換為新值,CAS操作偽碼描述如下:
清單1。CAS偽碼
BoolCAS(T*addr,Texpected,TnewValue)
{
if(*addr==expected)
{
*addr=newValue;
returntrue;
}
else
returnfalse;
}
在實際開發過程中,利用CAS進行同步,代碼如下所示:
清單2。CAS實際操作
do{
備份舊數據;
基于舊數據構造新數據;
}while(!CAS(內存地址,備份的舊數據,新數據))
就是指當兩者進行比較時,如果相等,則證明共享數據沒有被修改,替換成新值,然后繼續往下運行;如果不相等,說明共享數據已經被修改,放棄已經所做的操作,然后重新執行剛才的操作。容易看出CAS操作是基于共享數據不會被修改的假設,采用了類似于數據庫的commit-retry的模式。當同步沖突出現的機會很少時,這種假設能帶來較大的性能提升。
加鎖的層級
根據復雜程度、加鎖粒度及運行速度,可以得出如下圖所示的鎖層級:
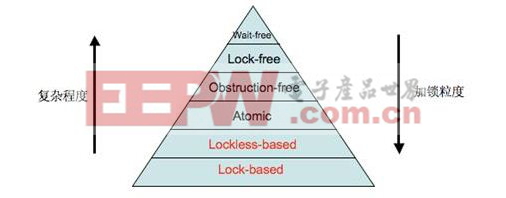
圖1。加鎖層級
其中標注為紅色字體的方案為Blockingsynchronization,黑色字體為Non-blockingsynchronization。Lock-based和Lockless-based兩者之間的區別僅僅是加鎖粒度的不同。圖中最底層的方案就是大家經常使用的mutex和semaphore等方案,代碼復雜度低,但運行效率也最低。
Linux內核中的無鎖分析
Linux內核可能是當今最大最復雜的并行程序之一,它的并行主要來至于中斷、內核搶占及SMP等。內核設計者們為了不斷提高Linux內核的效率,從全局著眼,逐步廢棄了大內核鎖來降低鎖的粒度;從細處下手,不斷對局部代碼進行優化,用無鎖編程替代基于鎖的方案,如seqlock及RCU等;不斷減少鎖沖突程度、降低等待時間,如Double-checkedlocking和原子鎖等。
無論什么時候當臨界區中的代碼僅僅需要加鎖一次,同時當其獲取鎖的時候必須是線程安全的,此時就可以利用Double-checkedLocking模式來減少鎖競爭和加鎖載荷。目前Double-checkedLocking已經廣泛應用于單例(Singleton)模式中。內核設計者基于此思想,巧妙的將Double-checkedLocking方法運用于內核代碼中。
當一個進程已經僵死,即進程處于TASK_ZOMBIE狀態,如果父進程調用waitpid()系統調用時,父進程需要為子進程做一些清理性的工作,代碼如下所示:
清單3。少鎖操作
984staticintwait_task_zombie(task_t*p,intnoreap,
985structsiginfo__user*infop,
986int__user*stat_addr,structrusage__user*ru)
987{
……
1103if(p->real_parent!=p->parent){
1104write_lock_irq(tasklist_lock);
linux操作系統文章專題:linux操作系統詳解(linux不再難懂)
linux相關文章:linux教程






評論