清華團隊發(fā)布3D DRAM存算一體架構!

近日,清華大學集成電路學院在2024 ACM/IEEE第51屆年度計算機體系結構國際研討會(ISCA)上發(fā)表了國際首款面向視覺AI大模型的三維DRAM存算一體架構,可大幅突破存儲墻瓶頸,并基于三維集成架構特點,實現相似性感知計算,進一步提高AI大模型的計算效率。
存算一體作為新一代計算技術,在數據運算和存儲過程中實現了一體化設計,被認為是后摩爾時代最重要的發(fā)展方向之一,將為人工智能的大規(guī)模應用提供不竭的算力支撐。在更早之前,中科院和清華大學就在該領域不斷鉆研,逐步突破。
一老問題:內存墻和IO墻的桎梏
理解該文前,需要對內存墻和IO墻現象進行基礎理解,這兩類現象來源于當前計算架構中的多級存儲。如圖所示,當前的主流計算系統(tǒng)所使用的數據處理方案,依賴于數據存儲與數據處理分離的體系結構(馮諾依曼架構),為了滿足速度和容量的需求,現代計算系統(tǒng)通常采取高速緩存(SRAM)、主存(DRAM)、外部存儲(NAND Flash)的三級存儲結構。
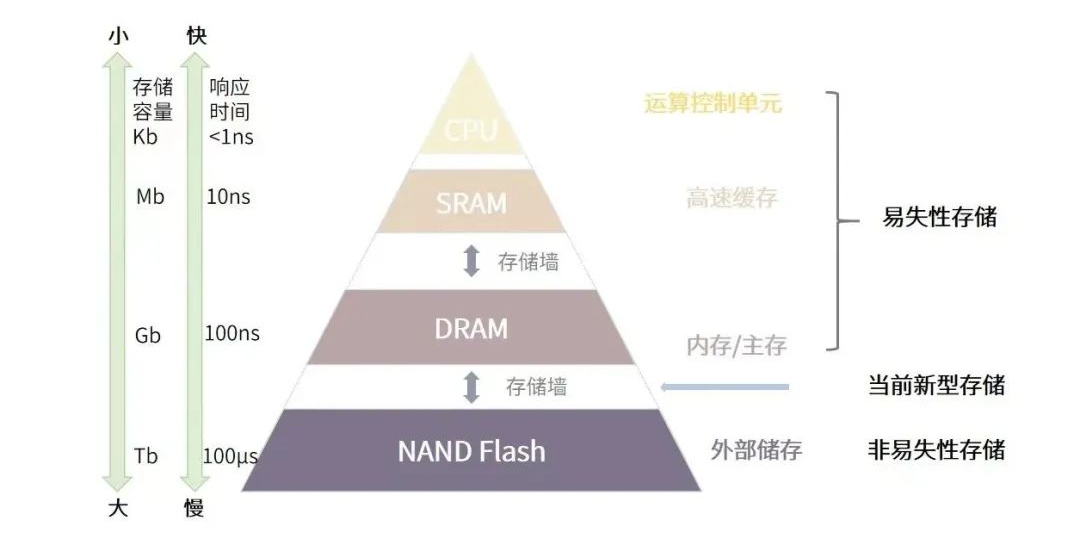
常見的存儲系統(tǒng)架構及存儲墻
(全球半導體觀察制圖)
每當應用開始工作時,就需要不斷地在內存中來回傳輸信息,這在時間和精力上都有著較大的性能消耗。越靠近運算單元的存儲器速度越快,但受功耗、散熱、芯片面積的制約,其相應的容量也越小。如SRAM響應時間通常在納秒級,DRAM則一般為100納秒量級,NAND Flash更是高達100微秒級,當數據在這三級存儲間傳輸時,后級的響應時間及傳輸帶寬都將拖累整體的性能,形成“存儲墻”。
IO墻則產生于外部存儲中,因為數據量過于龐大,內存里放不下就需要借助外部存儲,并用網絡IO來訪問數據。IO方式的訪問會使得訪問速度下降幾個數量級,嚴重拖累著整體性能,這即是IO墻。
現代處理器性能的不斷提升,而內存與算力之間的技術發(fā)展差距卻不斷增大。業(yè)界數據顯示,在過去的20多年中,處理器的性能以每年大約55%速度快速提升,而內存性能的提升速度則只有每年10%左右。并且,當代內存容量擴展面臨著摩爾定律的壓力,速度在逐年減緩的同時,帶來的則是成本的愈發(fā)高昂。隨著大數據AI/ML等應用爆發(fā),以上問題已經成為制約計算系統(tǒng)性能的主要因素。
二新問題:近存計算與“灘前問題”
據悉,岳志恒該論文題目為Exploiting Similarity Opportunities of Emerging Vision AI Models on Hybrid Bonding Architecture,尹首一教授,胡楊副教授為本文通信作者,岳志恒為論文第一作者,論文合作者還包括香港科技大學涂鋒斌助理教授,上海交通大學李超教授等。
更早以前,岳志恒就發(fā)表了題為Understanding Hybrid Bonding and Designing a Hybrid Bonding Accelerator《理解混合鍵合和設計混合鍵合加速器》的論文,可視為上文的前身。該文在3D DRAM基礎上,提出了一種利用CSE加速視覺AI模型的混合鍵合設計,并提供了混合鍵合設計的全面分析,在多種基準工作負載和數據集上評估,該項工作平均提高了5.69×~28.13×的能效和3.82×~10.98×的面積效率。總體而言,該文涉及了混合鍵合DRAM技術發(fā)展、I/O密度的限制和擴展的難題、2.5D TSV先進封裝的作用等內容。
存儲計算隨著時代的發(fā)展已出現各種新的問題和限制。在岳志恒的論文中,提到了近存計算與“灘前問題”兩個概念。近存計算則是近年行業(yè)廣泛采用HBM作為解決方案后,再輔以先進封裝方式將HBM芯片與計算芯片在silicon interposer上集成,以此計算芯片與存儲芯片近距離集成封裝,實現了計算單元與存儲單元之間數據的較短距離傳輸,通過“近存計算”提高處理性能。
在此突破下,此種高帶寬近存方案仍受到“灘前問題”制約。灘前問題是指,假設計算芯片是一個海島,則可以放置數據I/O通道的位置為島的沙灘位置,而沙灘的長度則是可以放置I/O的總長度。當受到信號串擾等因素約束時,相鄰的I/O位置受限,從而導致2.5D近存集成方案下I/O數量無法進一步提升,從而難以提升帶寬。
為了解決灘前問題,目前業(yè)界正逐步提高計算單元可用帶寬,如二維存內計算,就是基于DRAM的存內計算進一步將計算單元集成在存儲陣列內部,具體而言,在每個存儲Bank周圍集成計算單元,Bank數據讀出后,被相鄰計算單元立即處理,實現了Bank級別的存內計算,有效解決了二維近存方案的灘前問題。
二維存內計算也有著缺陷,論文提到,與先進邏輯工藝相比,集成于DRAM陣列內的計算電路性能有差距、面積代價高。同時,引入的計算單元將擠占DRAM存儲陣列面積,造成DRAM自身的存儲容量下降。例如,Samsung HBM-PIM在引入存內計算單元后,存儲容量減少了50%。
三清華突破:創(chuàng)新三維存算融合架構
針對近存架構的帶寬瓶頸和二維存內計算架構的工藝瓶頸問題,研究團隊首次探索了三維立體存算一體架構方案。此方案通過將計算單元與DRAM存儲單元在垂直方向堆疊,單元間以金屬銅柱作為數據通道互聯,有效解決了“灘前問題”,能任意位置放置數據I/O,大幅提高數據通路密度。DRAM陣列與計算邏輯可獨立制造,邏輯電路不受DRAM工藝限制,不影響存儲容量。
在本架構中,DRAM陣列由基本DRAM Bank組成,每個DRAM Bank與對應的計算Bank通過hybrid bonding工藝在垂直方向堆疊,二者通過高密度銅柱交互數據。互連銅柱距離短、寄生容抗小,數據通路等效于互連線直連,每個DRAM Bank與對應的計算Bank構成了Bank級存算一體單元(如圖1所示)。
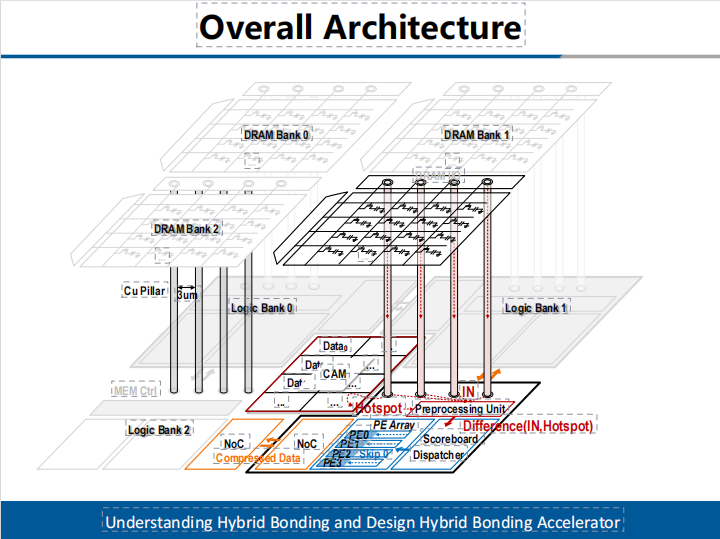
圖1,三維DRAM存算一體架構
團隊同時探索了Bank級存算一體架構下的設計空間,包括DRAM Bank適配的計算Bank算力,計算Bank的片上緩存大小,三維集成引入的面積開銷等;并深入分析了三維架構的硬件可靠性及散熱問題,實現了完整的存算一體架構設計,大幅突破了存儲墻瓶頸,對AI大模型運算,提供了有力的支持。
四相似性感知的三維存算一體架構
為進一步提升系統(tǒng)性能,設計團隊提出了相似性感知三維存算一體架構。實驗發(fā)現,激活數據在存儲陣列內連續(xù)存儲時,局部區(qū)域數據具有相似性,本文歸結為存儲數據的簇相似效應。利用此特性,設計團隊提出在三維存算一體架構內,每個計算Bank能夠獨立且并行地挖掘對應DRAM Bank內數據的相似性,并利用相似數據完成計算加速,提升系統(tǒng)性能。
該存算一體設計克服了三個關鍵技術難點:1.如何尋找相似數據。由于DRAM Bank空間大,遍歷搜索相似數據將引入極大的功耗和時間開銷;2.如何利用相似數據。先前存算一體單元并未針對數據相似性特點設計,無法充分挖掘其帶來的性能增益;3.如何平衡相似數據。由于在三維存算一體架構內,不同的計算Bank獨立并行,因此系統(tǒng)性能受制于負載最重的計算Bank。本存算一體架構為解決以上困難,提出了三項關鍵技術:
1
基于熱點機制的DRAM Bank相似數據搜索方案
研究團隊提出采用熱點機制完成快速的相似數據搜索。熱點數據為具有區(qū)域信息代表性的數據,即其與區(qū)域內多數數據有高相似性。本設計采用內容可尋址單元收集不同區(qū)域的熱點數據,新數據從DRAM Bank讀出時先在該單元內快速搜索匹配區(qū)域熱點數據,此熱點數據作為參考值與后續(xù)讀出數據執(zhí)行差分操作(如圖2所示)。由于數據之間存在相似性,因此差分結果往往具有高稀疏特性,可被用于計算加速。
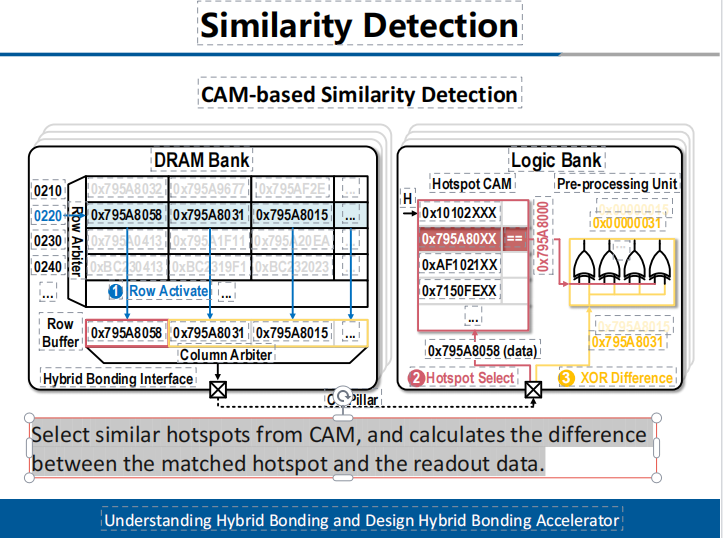
圖2相似性感知的硬件加速單元
2
針對相似數據特性的漸進式稀疏計算單元
當DRAM Bank數據讀出并經預處理單元差分操作后,由于熱點數據與DRAM Bank內區(qū)域數據具有相似性,異或結果往往在高比特位存在大量0值。針對這一稀疏特性,存算一體架構設計了漸進式稀疏檢測機構。先將完整數據按權重位置分塊,判斷數據比特塊是否全為0,若全0則直接跳過對應數據塊計算,非0部分由計分牌硬件單元迅速定位有效數據。完成稀疏檢測后,計分牌單元選擇將非冗余數據塊送入PE陣列進行計算,從而跳過了稀疏比特,提高了計算效率(如圖3所示)。
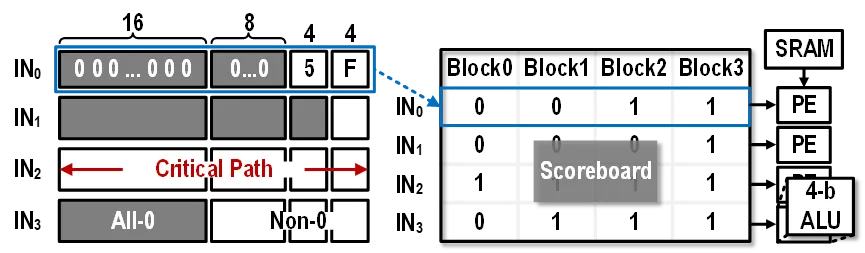
圖3漸進式稀疏計算單元
3
針對數據相似性差異的負載均衡機制
本存算一體架構采用Bank級并行,不同計算單元對應的DRAM Bank內數據相似性可能存在較大差別(如圖4所示)。這是因為數據相似性由硬件單元在運行時動態(tài)檢測,無法在任務映射時提前判別。針對不同計算Bank任務不均衡的問題,本方案借助DRAM Bank間的數據相似性,對任務負載進行壓縮處理,并在不同計算Bank間重分配任務,減少對片間路由網絡帶寬的擠占,實現Bank級別的負載均衡和性能提升。
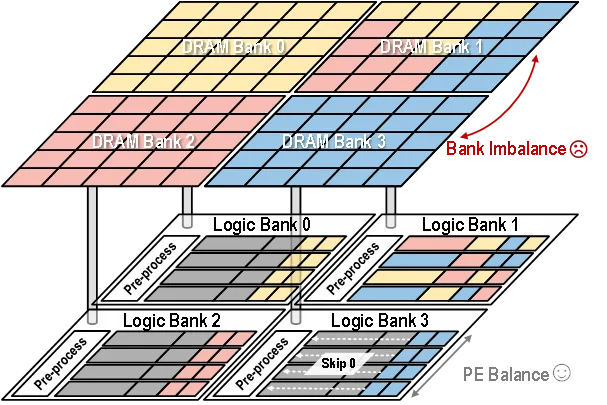
圖4由于數據相似性差異導致的負載不均衡
本工作完成了存算一體架構設計、單元電路實現及性能功耗面積分析。實驗結果顯示在系統(tǒng)性的AI任務負載上,本架構相比公開報道的高算力AI芯片,如Wormhole和TPUv3,3D基線實現了6.72倍和2.34倍的吞吐量提升。相似性技術進一步將吞吐量提高了1.21倍。(如圖5所示)在能效方面,3D基線相較于Wormhol和TPU實現了3.49倍和2.89倍的提升。數據相似性進一步提升了1.97倍的能效。(如圖6所示)
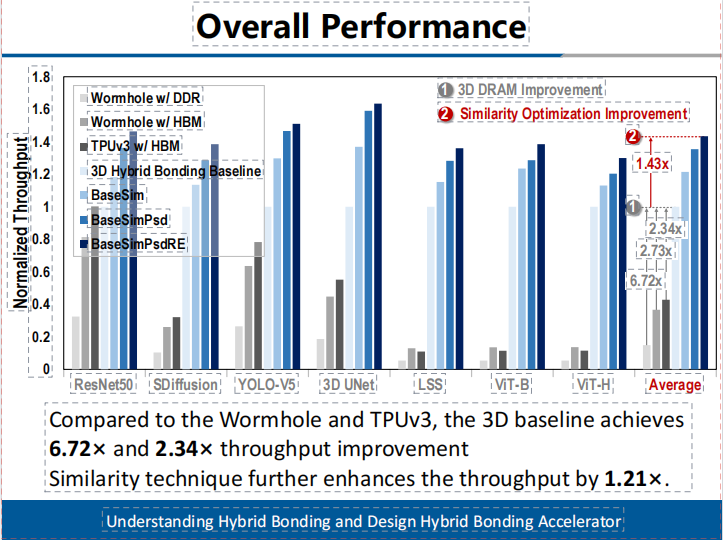
圖5有效吞吐提升
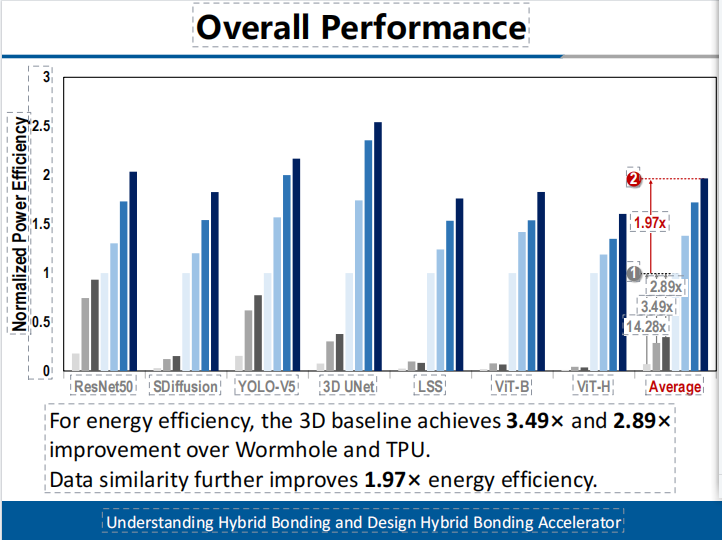
圖6有效能效提升
存算一體新突破,中科院、清華齊發(fā)力
在存算一體領域,我國科學院、高校堅持研發(fā)鉆研。今年2月,中國科學院微電子研究所劉明院士團隊研發(fā)出基于外積運算的數模混合存算一體宏芯片,設計了一種數模混合浮點SRAM存內計算方案,提出了模擬與數字存算宏的混合方法,結合了使用模擬存算方案進行高效陣列內位乘法和使用數字存算方案進行高效陣列外多位移位累加的優(yōu)點,達到整體上高能量效率與面積效率。通過殘差式數模轉換器架構,使數模轉換器所需分辨率僅為輸入位精度的對數,實現了高吞吐率和低開銷。通過基于矩陣外積計算數學原理的浮點/定點存算塊架構,矩陣-矩陣-向量計算可通過累加器元件完成。
該突破以“A 28nm 72.12TFLOPS/W Hybrid-Domain Outer-Product Based Floating-Point SRAM Computing-in-Memory Macro with Logarithm Bit-Width Residual ADC”為題發(fā)表在ISSCC 2024國際會議上,微電子所博士生袁易揚為第一作者,張鋒研究員與北京理工大學王興華教授為通訊作者。該研究得到了科技部重點研發(fā)計劃、國家自然科學基金、中國科學院戰(zhàn)略先導專項等項目的支持。
據悉,同之前的數字存算方案使用矩陣內積原理的大扇入、多級加法器樹相比,吞吐率更高。該架構還支持細粒度的非結構激活稀疏性以進一步提升總體能效。該存算一體宏芯片在28nm CMOS工藝下流片,可支持BF16浮點精度運算以及INT8定點精度運算,BF16浮點矩陣-矩陣-向量計算峰值能效達到了72.12TFLOP/W,INT8定點矩陣-矩陣-向量計算峰值能效達到了111.17TFLOP/W。這一研究結果為采用數模混合方案的存算一體架構芯片提供了新思路。
此外,去年10月,清華大學集成電路學院教授吳華強、副教授高濱團隊基于存算一體計算范式,研制出全球首顆全系統(tǒng)集成的、支持高效片上學習的憶阻器存算一體芯片,在支持片上學習的憶阻器存算一體芯片領域取得重大突破。該研究成果以“面向邊緣學習的全集成類腦憶阻器芯片”(Edge Learning Using a Fully Integrated Neuro-Inspired Memristor Chip)為題在線發(fā)表在《科學》(Science)上。
相同任務下,該芯片實現片上學習的能耗僅為先進工藝下專用集成電路(ASIC)系統(tǒng)的3%,展現出卓越的能效優(yōu)勢,極具滿足人工智能時代高算力需求的應用潛力,為突破馮·諾依曼傳統(tǒng)計算架構下的能效瓶頸提供了一種創(chuàng)新發(fā)展路徑。
吳華強介紹,存算一體片上學習在實現更低延遲和更低能耗的同時,能夠有效保護用戶隱私和數據。該芯片參照仿生類腦處理方式,可實現不同任務的快速“片上訓練”與“片上識別”,能夠有效完成邊緣計算場景下的增量學習任務,以極低的耗電適應新場景、學習新知識,滿足用戶的個性化需求。
*博客內容為網友個人發(fā)布,僅代表博主個人觀點,如有侵權請聯系工作人員刪除。